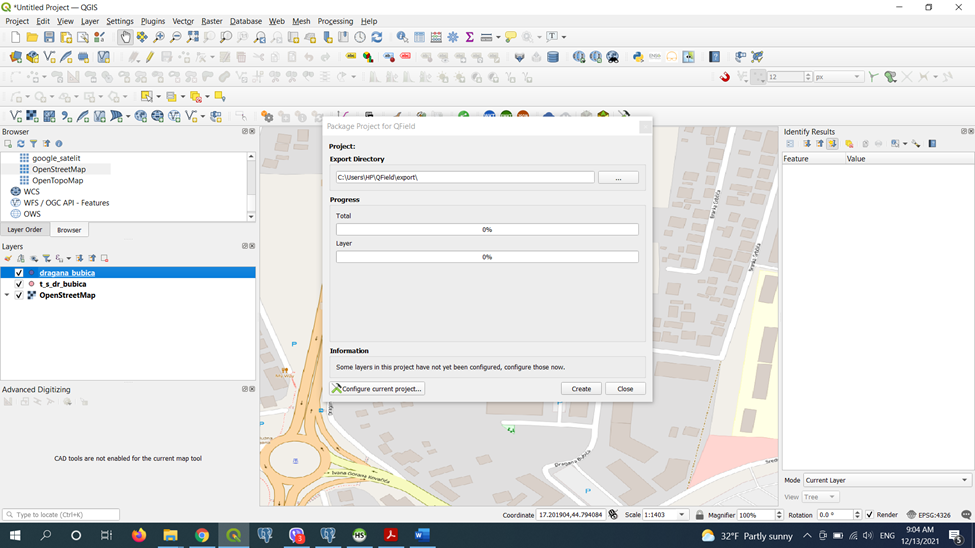
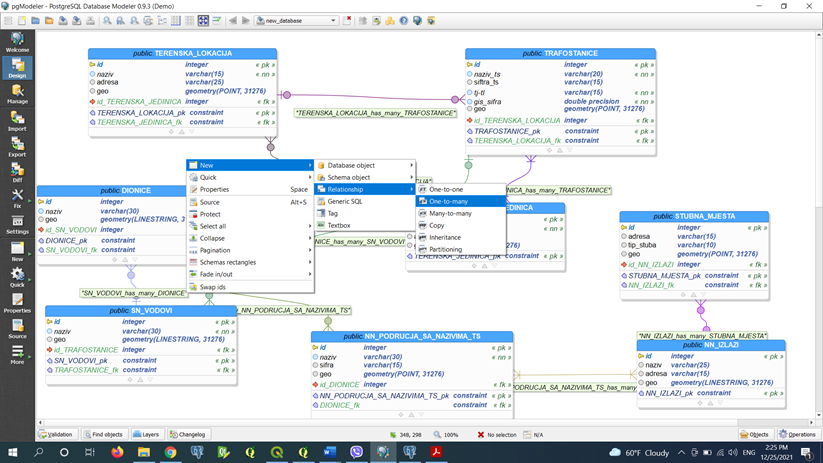
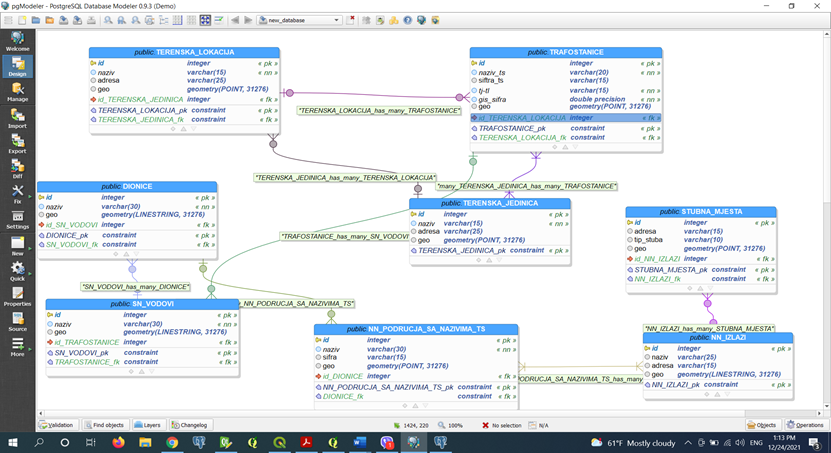
All the spatial data imported into our tables are not very useful if we do not have the appropriate tools needed to use and extract the necessary information from it. Spatial queries provide a way to process a huge number of records in a very short time.
Nowadays, almost every domain of business, whether it is small online stores or large corporations, uses data. This data is managed using databases. This is why database administrators, especially those with knowledge of SQL databases, are in high demand.
Data is at the core of many web and mobile applications. For example, an application like Facebook contains information about the user, his friends, posts, etc. Databases are used to store this data. SQL is a programming language that allows developers to manipulate that data.
The abbreviation SQL refers to Structured Query Language, i.e. structured query language.
According to the W3School definition: "SQL is a standard language for storing, managing and retrieving data in databases".
Basically, it is a language that allows communication with databases and management of all the data they contain
The concept of SQL was first developed in the 1970s by Edgar F. Codd, a pioneer in relational database management. He wanted to create a system that would facilitate the management of shared databases. IBM engineers Donald D. Chamberlin and Raymond F. Boyce accepted the theory behind Codd's research and began developing the concept, using it to search for information in System R, the company's semi-relational database.
IBM continued to develop the technology and initially called SQL SEQUEL (Structured English Query Language), and in 1979 Oracle (then called Relational Software) released the first commercial version of the system. SEQUEL was later renamed SQL, as SEQUEL was a trademark of the British company Hawker Siddeley Dynamics Engineering Limited.
This programming language has various uses in the field of data analysis, and is particularly useful because it can:
• - Execute queries against the database
• - Retrieves data from the database
• - Updates records in the database
• - Deletes records from the database
• - Creates new databases, or new tables in the database
• - Creates save and review procedures in the database
Example of a query for the length of the 110 kV transmission line of Elektrokrajine Elektrodistrbutivni predusje. For geometric data types, returns the 2D Cartesian length of the geometry if the data is Linestring, MultiLineString, St_Curve, ST_MultiCurve. Length units are in meters.
Query for streets with only one substation. In this query, you can notice the use of the JOIN clause, which combines the joining of tables, their rows and data. In SQL queries, fields are always grouped first with the group by command, after which the having command is withdrawn. Finally, count the necessary data with the count command.
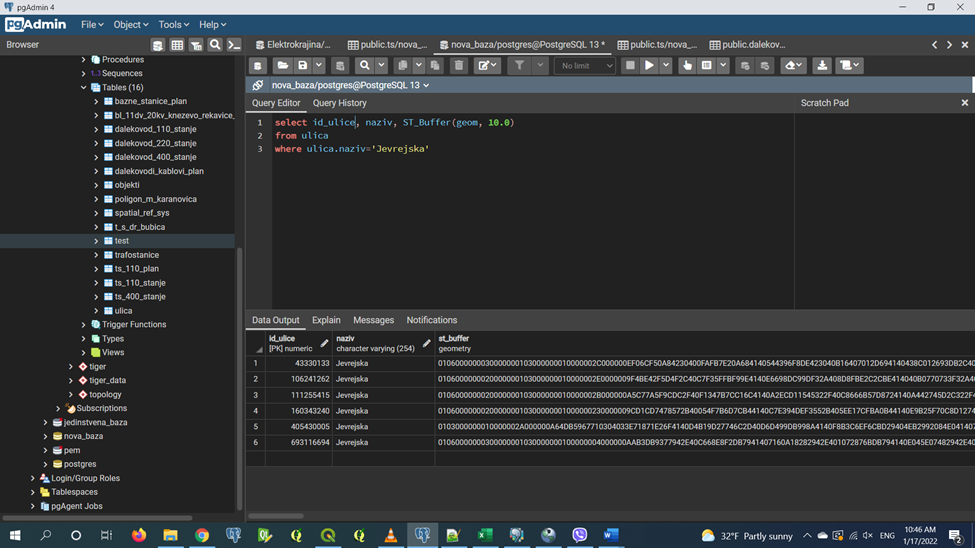
The ST_Buffer function encircles a geometric object at a specified distance and returns a geometric object that is a buffer that surrounds the original object. In this example, we are looking for data on which substations are located in Jevrejska Street.
A separate number of substations for each street.
The ST_Distance function calculates the shortest distance between two geometries. In this task, the cross join command is used, which combines each row from the first set of rows with each row from the second set of rows. This command is used when a normal connection cannot be used. In this task, it is very important that the data type is not recorded as geometry, but geography, due to the accuracy of the data and the mathematical way of calculating the data.
Example query to compare distances between geometries and compare results with Web Merkator distances. In the spwgs84 column, the Spheroidal distance was calculated, which was compared with the WM distance. As you can see, the distance is different, the spheroid is better for measuring.
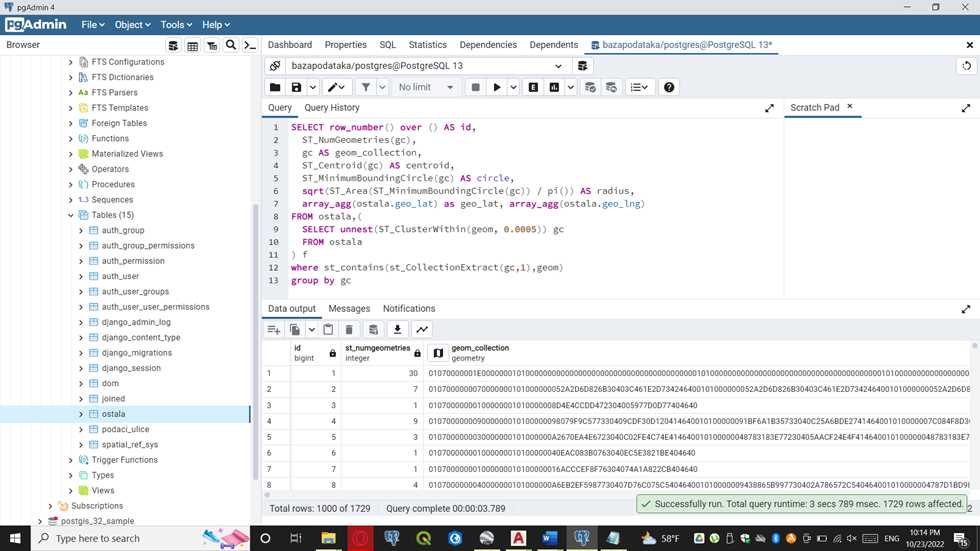
Sample for clustering data with postgis function. Data was points with coordinates lat and long, i want to cluster groups of data with same position. We have two ways to do that.
First way with postgis functions and form cluster in radius,
Second way is clean sql, where is not used postgis functions to form cluster of points with identical coordinates. In clean sql we cant calculate radius of points or dimension of polygons to determinate our groups.